
Researchers Deeply Mine a Universe of Peptides Encoded by Long Noncoding RNAs
Long noncoding RNAs (lncRNAs), a family of non-coding RNAs (ncRNAs) that are greater than 200 nucleotides in length, were formerly regarded as "junk RNAs" due to the lack of long or conserved open reading frames (ORFs). Recently, however, a growing amount of evidence has demonstrated that many short or small open reading frames (smORFs) embedded in lncRNA transcripts are able to encode functional polypeptides (smORFs-encoded polypeptides, SEPs). Most importantly, thousands of additional lncRNA transcripts with smORFs were discovered, suggesting that SEPs may represent a large albeit neglected portion of non-annotated peptides involved in diverse physiological process. Therefore, large-scale discovery and functional characterization of unknown SEPs might provide new clues for the annotation and functional analysis of noncoding elements in the genome and their effects on biological evolution.
In a recent study published in Molecular and Cellular Proteomics, Prof. YANG Fuquan's group and Prof. CHEN Runsheng's group from the Institute of Biophysics, Chinese Academy of Sciences, implemented a novel strategy for SEP discovery and characterization, which enabled the discovery of 762 novel SEPs from different human and murine cell lines and tissues, representing the largest number of MS-detected SEPs ever to be reported.
The improved SEP discovery rate can be attributed to an optimized MS-based workflow by combining a de novo construction of a high-quality putative SEP database with two effective and complementary polypeptide enrichment methods. The researchers take advantage of NONCODE, a repository containing the most complete collection and annotation of lncRNA transcripts from different species, to build a novel database that maximize a collection of SEPs from human and mouse lncRNA transcripts. The combination of 30 kD MWCO membrane filtration and C8 SPE for SEP enrichment also promote the discovery and identification of novel SEPs from different cell cultures and tissues.
The increased number of discovered SEPs in this study provides new opportunities to gain deeper insights into their physical and chemical properties. For instance, bioinformatic analysis reveals that the physical and chemical properties of these novel SEPs were varied from canonical proteins. More than 60% of the identified SEPs from both human or mouse are initiated by unknown start codons (i.e. non-AUG), which typically have reduced efficiency when compared with AUG codons. Moreover, SEPs are commonly shorter in amino acid length and enriched with more basic residues, which are typical features of known coding genes lacking mass spectrometry evidence.
Most importantly, the hundreds of SEPs discovered in this study can not only provide new clues for the annotation of noncoding elements in the genome, but might also serve as a valuable resource for the functional characterization of individual SEPs and the exploration of the possible mechanism of lncRNA translation.
This work was supported by the National Natural Science Foundation of China (91640112 and 31670185) and the National Key Research and Development Program of the Ministry of Science and Technology of China (2018YFA0106901 and 2017YFC0907503).
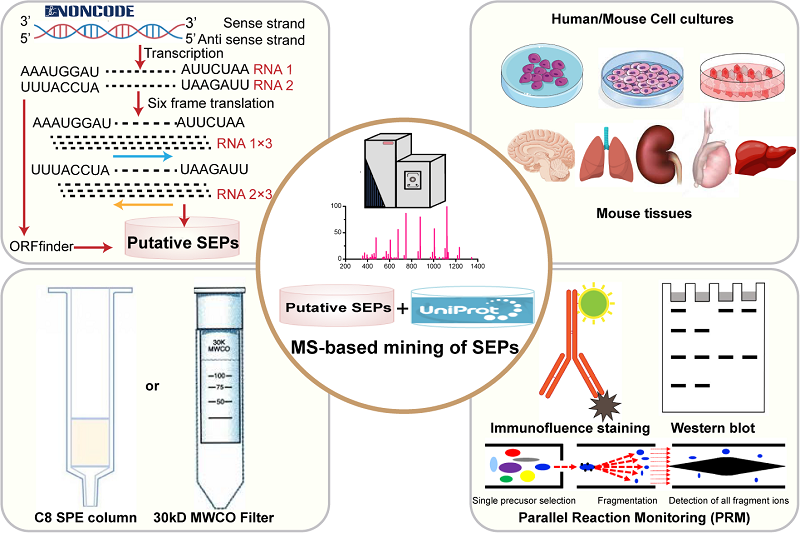
Strategy used for deeply mining of peptides encoded by long noncoding RNAs
(Image by YANG Fuquan's group)
Article link: https://www.mcponline.org/article/S1535-9476(21)00081-5/fulltext#secsectitle0150
Contact: YANG Fuquan
Institute of Biophysics, Chinese Academy of Sciences
Beijing 100101, China
Email: fqyang@ibp.ac.cn
(Reported by Dr. YANG Fuquan's group)